
A little more detail about the Pipeline:
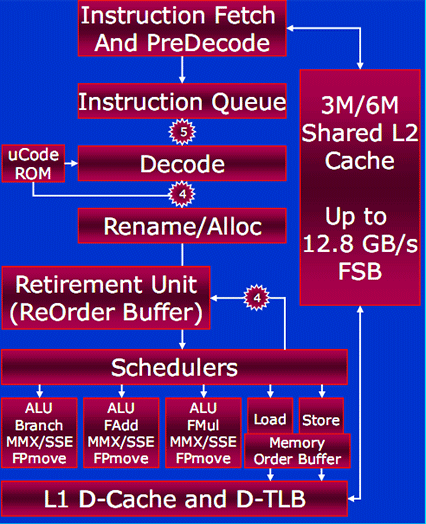
The pipeline has not changed from the 14-stage pipeline that was in Conroe (we found out Nehalem will have more - roughly 20-24 stages - and will already know it will bring back HyperThreading in some shape or form). Instructions first enter the pipeline at Instruction Fetch and PreDecode.Predecode is a decoding of the length of the instruction before it actually reaches the decode unit, so the CPU knows how long instructions are and which decoders need to operate on which instructions. The data is then passed into an Instruction Queue which is 64 bytes deep in order to absorb temporary pipeline stalls that can occur between PreDecode and Decode.
A maximum of five instructions can be passed through from the Instruction Queue to Decode, but this is then dropped to four from Decode to (Micro-op) Rename and Allocation.
The Decode unit goes through a "template" that can process one complex and three simple instructions per clock-cycle. "Simple" instructions are like register or memory based instructions, for example, a Read-Modify-Write instruction would be broken up into firstly a load into temporary registry, then add, then store back to memory. With Penryn this specific function is supported with the hardware Decoder unit but still takes two clock-cycles.
 Conversely, complex decoding like an "FXSAVE", which saves all FP-SSE states to memory, can take something like 100 micro-instructions to do this. However, these types of instructions aren't executed that often so the uCode ROM takes over at this point.
Conversely, complex decoding like an "FXSAVE", which saves all FP-SSE states to memory, can take something like 100 micro-instructions to do this. However, these types of instructions aren't executed that often so the uCode ROM takes over at this point.The uCode ROM element attached to the Decode is what contains the MMX and SSE instructions, and is used to sequence instructions that are more complex than can be processed through the hardware decoders: the two cannot work concurrently and both of these decoders can process up to four micro-ops per instruction.
The (Micro-op) Rename and Allocation element basically sets of the execution of instructions for OoO (Out of Order) behaviour. As the decoded instructions are renamed they are assigned to a particular Retirement Unit before being computationally processed.
The Retirement Unit and ReOrder Buffer has 96 entries available and also appropriately organises the data and allows for the Out of Order execution, before it is sent to the Shedulers which fires off the data into the appropriate computational unit, into Cache, or external memory to be stored. The Shedulers are 32 entries wide and are capable of five execution operations per cycle.
Up to three concurrent simple integer operations can be processed in the executions units, however floating point operations require specific units: there is only one Add, one Multiply and one Miscellaneous, which is fine if you need to process an Add and Multiply, but if two Adds drop down the pipeline, one is held in the Schedulers until the execution unit is finished with the first and ready for the second. In the grand scheme of things though, this isn't a problem because of the Out of Order execution, internal buffering and massive clock rate.
The Retirement Unit and ReOrder Buffer doubles up as a temporary result storage for data that has been passed through the three 64-bit ALU-based computational execution units, before being sent down the pipe to Load or Store which also has its own Memory Order Buffer. This Memory Order Buffer is another Out of Order engine for scheduling load and store operations and was noted as being "a fairly tricky aspect of the micro architecture" by Intel's Steve Fischer during our discussions with him.
It has to work its data on its relevance to the order of other data, relative to other loads and stores. So if a store operation is older than another load then it needs to be checked to make sure that load has no dependency on that store, otherwise it will return incorrect data. If there is no dependency then the load is dispatched before the store, so performance is increased.
Included in the buffer is a limited history table which labels where things have gone and how long ago it left, so it can read this without having to snoop Cache or memory which takes time. However it still makes Loads speculatively, so if that speculation fails then it has to not only reissue them from all the way back up to the Instruction Queue part of the pipeline, but it has to wait until the pipeline opens before it can be reissued. So the efficiency and accuracy of the predictor is key to performance, but in Penryn the Memory Order Buffer hasn't been upgraded from Conroe because it was felt that the extra power trade off it would have needed to provide the extra performance didn't give a net win.
A lot of the processor work overhead is to efficiently manage all the data that arrives the first half of the CPU works on the instructions that flow through in order, but combining them where possible with Macro-ops and Micro-ops Fusion to reduce computational load later.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04


Want to comment? Please log in.